

Nel post di oggi andiamo avanti con la serie di articoli sulle reti neurali, e rimaniamo concentrati sull’ottimizzazione della funzione di costo. Nel post precedente, che trovi qui sotto, abbiamo visto il metodo di discesa del gradiente nel caso scalare.
Metodo di discesa del gradiente (caso scalare)

Nell’articolo introduttivo alla matematica delle reti neurali, che trovi qui sotto, abbiamo visto che uno dei passaggi fondamentali per ottenere buona rete, in grado di risolvere il problema che ci interessa, è minimizzare una funzione di costo/loss.
Oggi, con l’aiuto del video che ho pubblicato ormai 5 anni fa su YouTube, e che trovi associato a questo post, vediamo di generalizzarlo a funzioni vettoriali.
Prima di proseguire con l’algoritmo e la descrizione qui sotto, ti consiglio fortemente di guardare il video perchè credo che l’intuizione grafica e geometrica sia molto più facile da comprendere lì che nelle formule qui sotto.
Descrizione dell’algoritmo
Consideriamo una funzione
regolare abbastanza. Ti ricordo che il gradiente di una funzione scalare in un punto x è un vettore che ha tante entrate quante le componenti di x, dove le entrate corrispondo alle derivate parziali rispetto alle corrispondenti componenti:
Probabilmente già sai che il gradiente di una funzione scalare in un punto determina la direzione ortogonale all’insieme livello di quel punto.
")
Ti ricordo inoltre che l’insieme di livello di un punto x è definito come segue
Notiamo inoltre che, usando l’espansione in serie di Taylor intorno ad un punto x, si può scrivere
dove
è una notazione per raccogliere tutti i termini che dipendono almeno quadraticamente da v. Supponendo che v sia abbastanza piccolo, possiamo quindi trascurare questi termini quadratici, e approssimare la funzione in un punto x+v con il valore che essa ha in x a cui dobbiamo aggiungere un termine che dipende sia da v che dal gradiente nel punto x.
La cosa interessante, a questo punto, è notare che nel caso in cui v sia allineato con il gradiente di f in x, andremo a massimizzare la variazione della funzione, dato che per la disuguaglianza di Cauchy-Schwarz vale che
dove il coseno è dell’angolo compreso tra i due vettori. Per cui, dato che il coseno vale 1 per l’angolo zero, notiamo che se v punta nella direzione del gradiente di f in x, avremo il coseno massimo. Similmente, nel caso la direzione sia questa ma il verso sia opposto, otteniamo un angolo tra i due vettori di 180°, e quindi un coseno di -1.
Ricordiamo ora che il nostro interesse è risolvere il seguente problema di minimizzazione:
Il ragionamento fatto sopra, ci suggerisce quindi che andare nella direzione opposta del gradiente di f in un punto potrebbe essere una buona idea. Infatti questa scelta, almeno localmente, ci permette di ottenere la massima decrescita del valore della funzione. Siamo quindi pronti per introdurre il metodo della discesa del gradiente.
L’algoritmo
Come nel caso scalare, il metodo di discesa del gradiente è un metodo iterativo. Ciò vuol dire che partiamo da una posizione iniziale ragionevole o casuale x_0, e cerchiamo pian piano di migliorarla. Il processo continua fino a quando non raggiungiamo un livello desiderabile di approssimazione del minimo.
L’algoritmo è quindi definito come segue:
dove L>0 è la costante di Lipschitz del gradiente, ovvero
In questo articolo non andremo a vedere perchè sia necessario questo limite superiore del passo tau. Dedicheremo uno dei prossimi articoli a questo tema.
Ci tengo però a far notare che il metodo non fa altro che cercare di diminuire il valore attuale della funzione, f(x_k), andando nella direzione che, localmente, ci fornisce la massima decrescita. Il passo tau ci permette di controllare quanto ci allontaniamo dalla posizione attuale, e, intuitivamente, non possiamo prenderlo troppo grande perchè altrimenti smettiamo di avere a che fare con una direzione di decrescita.
Dietro il vincolo che 0<tau<2/L c’è l’ipotesi che il gradiente di f sia L-Lipschitz. Questa è spesso accoppiata all’ipotesi che f sia (strettamente) convessa, per garantire l’esistenza (e unicità) di un minimo globale e tassi di convergenza ottimali del metodo. Per ora non mi ci soffermo molto, ma dedicherò il prossimo articolo ad introdurre cosa sia una funzione convessa, e poi andremo a vedere le proprietà di convergenza del metodo nel successivo.
Esempio semplice
Consideriamo un esempio semplice, ovvero
Il gradiente di f è il seguente
che è una funzione 1-Lipschitz, ovvero L=1, dato che
Ciò significa che il metodo di discesa del gradiente in questo caso diventa
Qui iniziamo ad intuire il perchè del vincoli che tau sia minore di 2, dato che se non lo fosse non andremmo a diminuire la norma. Infatti, abbiamo che
e la funzione (1-tau)^2 è più piccola di 1 solo se tau è tra 0 e 2:
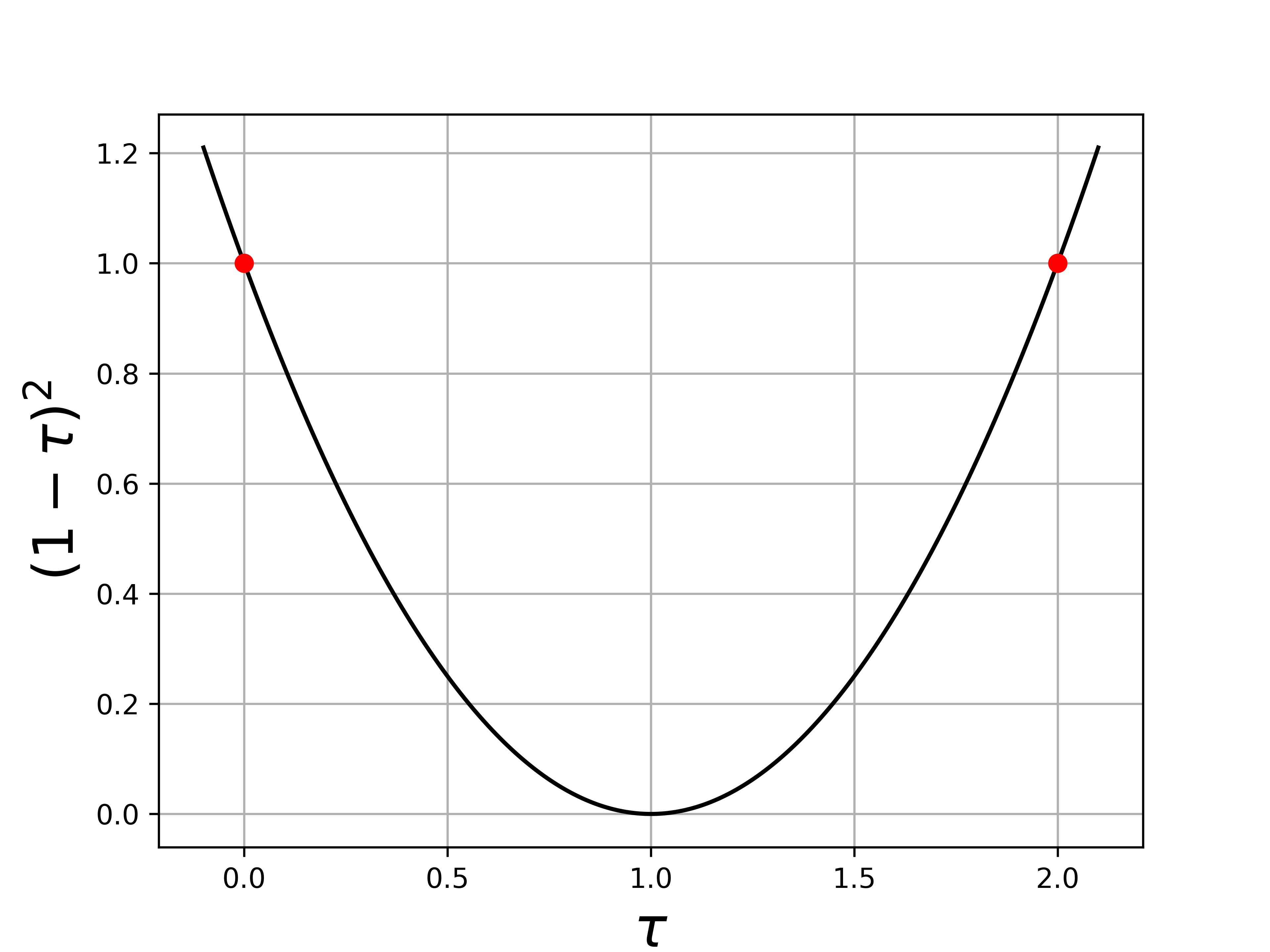
Prendiamo per esempio tau=0.5, quindi il metodo diventa
e quindi si vede che se consideriamo il criterio d’arresto
andremo a fare
passi.
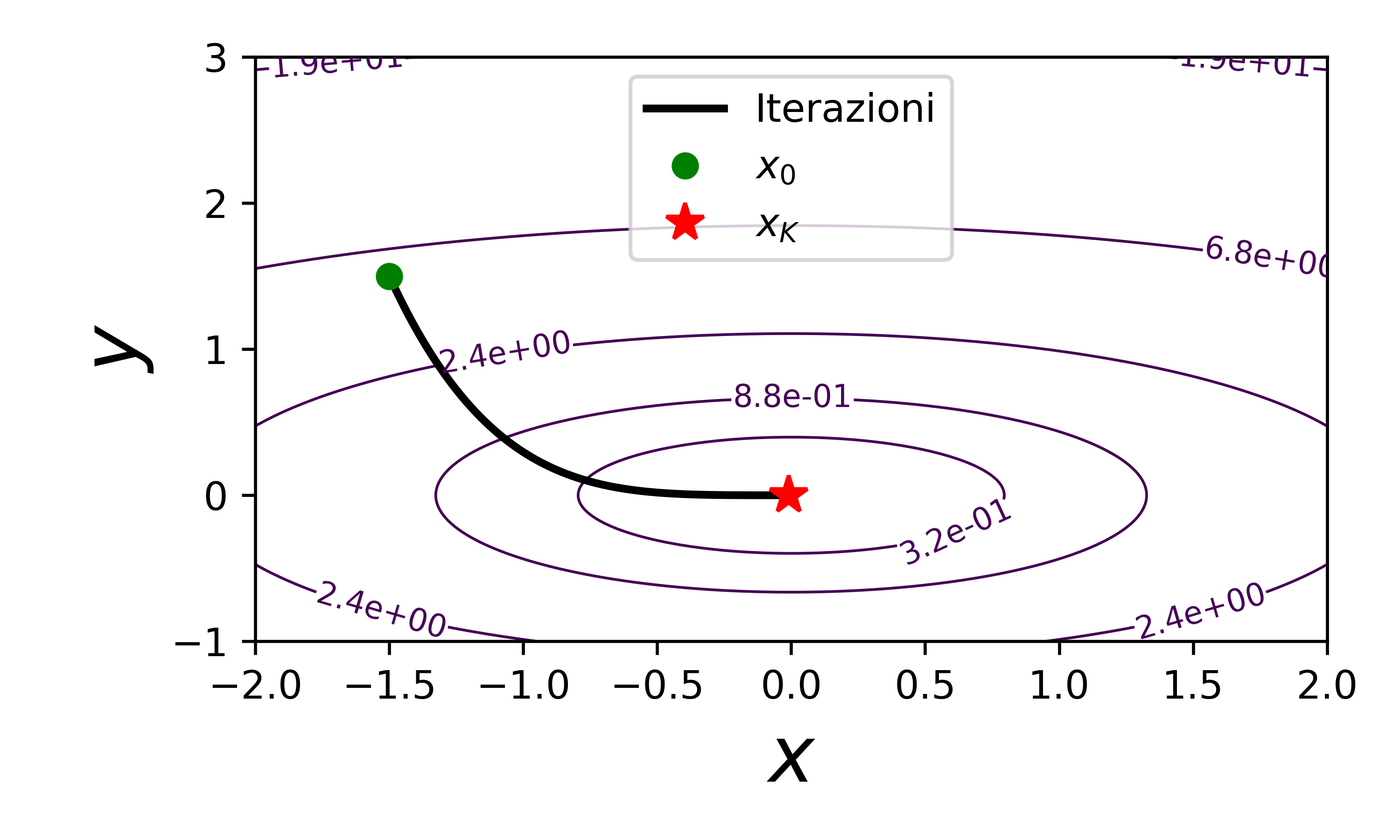
Conclusione
Spero che l’articolo ti sia risultato piacevole ed interessante! Se hai domande scrivi pure nei commenti che cerco di leggere frequentemente.



